“Let Them Choose Their Strategies!” Expert Aggregation and Multi-Players Multi-Armed Bandits for Internet of Things Networks
Abstract
Decentralized access of several dynamic devices accessing a stationary wireless network
can be modelled by the multi-player multi-armed bandit framework.
It can model Internet of Things networks, and many different learning strategies have been proposed recently.
Instead of choosing a specific algorithm offline,
we propose to use an online aggregation algorithm
to automatically let each object decide, on the fly, the best algorithm to use in a certain setting.
Simulation results justify the interest of our proposal in different problems.
Keywords:
Cognitive Radio,
Reinforcement Learning,
Multi-Player Bandits,
Multi-Armed Bandits,
Expert Aggregation.
1 Introduction
The model of Opportunistic Spectrum Access (OSA, [11]) for Cognitive Radio (CR, [9]), considers one Secondary User (SU) trying to use a licensed radio network, slotted both in time and frequency, and occupied by Primary Users (PU). The network usage from the PU determines the availability patterns of the radio channels, and the goal of the SU is to communicate as efficiently as possible, without interfering with the PU. Thus at each step, a SU first senses one channel, and only transmits if this channel is unoccupied by a PU. A common model in the literature is to describe the PU impact on the availability of the channels in the following way: channels are independent and identically distributed (i.i.d.), and their qualities follow parametric distributions, e.g., Bernoulli of means for availabilities when dealing with binary sensing feedback. The SU has to select the best expected channel each time to maximize its throughput, or if successful communications are seen as rewards, the SU has to maximize its cumulative rewards, as in the Multi-Armed Bandit (MAB) problem [6].
MAB learning algorithms are known to be useful for the OSA setting [11], and algorithms and other variants (e.g., - or Bayes-UCB, [7, 6]) have been successfully applied to both numerically and physically simulated CR problems [8]. The performance of such learning algorithm can be measured by different criteria. It is common in the bandit literature to study the regret [6], which compares the reward in rewards between the algorithm and the full-knowledge strategy which always picks the best arm, i.e., the most available of mean . Good algorithms are expected to have slow-growing expected regret, but other criterion include the best arm pull frequency, or when applied to the CR problem, the throughput of the SU.
Many different learning algorithms have been proposed by the machine learning community [6], and most of them depend on several parameters, for instance for , the prior for Thompson sampling, the function for - etc. Every time a new MAB algorithm is introduced, it is compared and benchmarked on some bandit instances, parameterized by , usually by focusing on its expected regret . For a known and specific instance, simulations help to select the best algorithm in a pool of algorithms. But when one wants to tackle an unknown real-world problem, one expects to be efficient against any problem, of any kind, size and complexity. Ideally one would like to use an algorithm that can be applied identically against any problem, or at least any problem within a certain class. To choose the best algorithm, two approaches can be followed: either extensive benchmarks are done beforehand – if this is possible – to select the algorithm and its optimal parameters, or an adaptive algorithm is used to learn on the fly its parameters.
For the development of CR, a crucial step is actually to insert multiple smart devices in the same background traffic. With the presence of a central controller that can assign the devices to separate channels, this amounts to choosing at each time step several arms of a MAB in order to maximize the global rewards, and can thus be viewed as an application of the multiple-play bandit. Due to the communication cost implied by a central controller, a more relevant model is the decentralized multi-player multi-armed bandit model [1], in which devices select arms individually and radio collisions may occur, which yield a zero reward. The goal for every player is to select one of the best arms, as much as possible, without colliding too often with other devices. A first difficulty relies in the well-known trade-off between exploration and exploitation: devices need to explore all arms to estimate their means while trying to focus on the best arms to gain as much rewards as possible. The decentralized setting considers no exchange of information between devices, that only know and , and to avoid collisions, devices should furthermore find orthogonal configurations (i.e., the devices use the best arms without any collision), without communicating. Hence, in that case the trade-off is to be found between exploration, exploitation and low collisions.
Combining two of our recent works, we propose to use our aggregation algorithm Aggregator from [3], in combination with different multi-player MAB algorithms from [1] and [4]. We present below our mathematical model, then our contribution is stated as a three-part proposal, and the iconic UCB algorithm is presented. Simulation are presented for the two cases of and devices.
2 Multi-Player Stationary Bandit Model
We consider radio channels, also called arms, of different characteristics, unknown to identical objects that have to communicate to a fixed gateway, in a decentralized and autonomous manner. Following the classical OSA model [11], the radio protocol is slotted in both time and frequency. At each time step , each device tries to communicate in a channel . The device is a SU: it first senses (only) one channel at a time, and can use it to communicate only if it was sensed free from any PU (i.e., PU have full priority over the SU).
We choose to restrict to a stochastic model: after choosing the arm , it is assumed that the sensing provides a reward , randomly drawn from a certain distribution depending on the arm index. Rewards are assumed to be bounded in , and generally they follow one-parameter exponential families. We restrict to Bernoulli distributions, for sake of simplicity, meaning that arm has a parameter . Rewards are drawn from , , which can be simply interpreted by the SU: it is if the channel is not used by any PU during the time slot , and is otherwise.
The multi-player MAB setting considers devices [4], that have to make decisions at some pre-specified time instants. At time step , device selects an arm , independently from the other devices’ selections. A collision occurs at time if at least two devices choose the same arm. A collision occurs at time for device if . Each device then receives (and observes) the binary rewards . In words, it receives the reward of the selected arm if it is the only one to select this arm, and a reward zero otherwise. Other models for rewards reward have been proposed, but we focus on full reward occlusion. This common setup is relevant to model the OSA problem: the device first checks for the presence of primary users in the chosen channel. If this channel is free (), the transmission is successful () if no collision occurs with other smart devices ().
A multi-player MAB strategy is a tuple of arm selection strategies for each of the devices, and the goal is to propose a strategy that maximizes the total reward of the system, under some constraints. First, each device should adopt a sequential strategy , that decides which arm to select at time based on previous observations.
The performance of a multi-player strategy is measured using the mean regret, i.e., the performance gap with respect to the best possible strategy. The regret of strategy at horizon is the difference between the cumulated reward of an oracle strategy, assigning in this case the devices to the best channels, and the cumulated reward of strategy . Denote the best mean by , the second best etc. The regret is then defined as
| (1) |
Maximizing the expected sum of the global reward of the system is equivalent to minimizing the regret, and the simulation results below present regret plots of various decentralized multi-player algorithms. It is known that any policy in this setting cannot beat the (asymptotic) lower-bound [1]. The algorithms we compare typically achieve the lower-bound up-to constant factors: they have logarithmic regret profiles as seen in the simulation plots, and MCTopM-- actually achieves the best known regret upper-bound [4], in the form of with a constant proportional to and depending on the difficulty of the problem (i.e., of the gaps between successive means ).
3 Three Blocks for our Proposal
Our proposal consist in using: classical single-player index policies for channel selection, collision avoidance strategies for the multi-player aspect, and an aggregation algorithm that each device implements, to select on the fly either the best index-policy or the best collision-avoidance (or possibly both, but we do not include more simulations due to space constraints).
3.1 Single-Player Index Policies
Upper Confidence Bounds algorithms [6] use a confidence interval on the unknown mean of each arm, which can be viewed as adding a “bonus” exploration to the empirical mean. They follow the “optimism-in-face-of-uncertainty” principle: at each step, they play according to the best model, as the statistically best possible arm (i.e., the highest UCB) is selected. is called an index policy. In our model, every dynamic device implements its own algorithm, independently. Algorithm 1 presents the pseudo-code of .
More formally, for one device, let be the number of times channel was selected up-to time , . The empirical mean estimator of channel is defined as the mean reward obtained by selecting it up to time , . For , the confidence term is given by [2] , giving the upper confidence bound , which is used by the device to decide the channel for communicating at time step : .
Other algorithms The - algorithm is similar, but instead it uses a Kullback-Leibler divergence function to compute a statistically better UCB [7]. The Thompson sampling (TS) [10] algorithm is Bayesian: it maintains a posterior distribution on each means (e.g., Beta posteriors for Bernoulli arms), updated after each observation, and chooses an arm by sampling a random mean from each posterior and playing the arm with highest mean. Both , - and TS have been proved to be efficient for stationary bandit problems, and were used in the experiments in both of previous papers [3, 4].
3.2 Collision Avoidance Strategies
Each object uses an index policy on its own, using the sensing information to estimate the quality of each channel, and use a collision avoidance strategy to deal with other devices. We consider three strategies, from [1], and RandTopM and MCTopM from our recent work [4]. For one object, the strategy consists in using a dynamic rank in and selecting the -th best arm (as given by the index policy) instead of the best one. When facing a collision, a new uniform rank is selected.
Our algorithms work similarly but they are more direct: the object still plays always in a set of its estimate of the best arms, but instead of relying on a rank to select its arm it simply plays one of the best arms. As long as the chosen channel is still one of the best one, and no collision is observed, the device keeps using it. MCTopM is a modification of RandTopM: after a good transmission, a device can fix itself on a channel and ignore further collisions as long as its channel is still estimated as one of the best channels. MCTopM performs theoretically better and usually empirically outperforms the two others.
3.3 Online Algorithms Selection
We assume to have MAB algorithms, , and let be an aggregation algorithm, which runs the algorithms in parallel (with the same slotted time), and use them to choose its channels based on a voting from their decisions. depends on a pool of algorithms and a set of parameters. A good aggregation algorithm performs almost as well as the best of the , with a good choice of its parameters, independently of the MAB problem, and performs similarly to the best of the . The aggregation algorithm maintains a probability distribution on the algorithms , starting from a uniform distribution: is the probability of trusting the decision made by algorithm at time . then simply performs a weighted vote on its algorithms: it decides whom to trust by sampling from , then follows ’s decision.
Our proposal is called Aggregator, and it is detailed in Algorithm 1 in [3]. It is easy to implement, it requires no parameter to tune and it was showed to out-perform all the others state-of-the-art expert aggregation algorithm for stationary problems.
4 Experiments on Simulated Problems
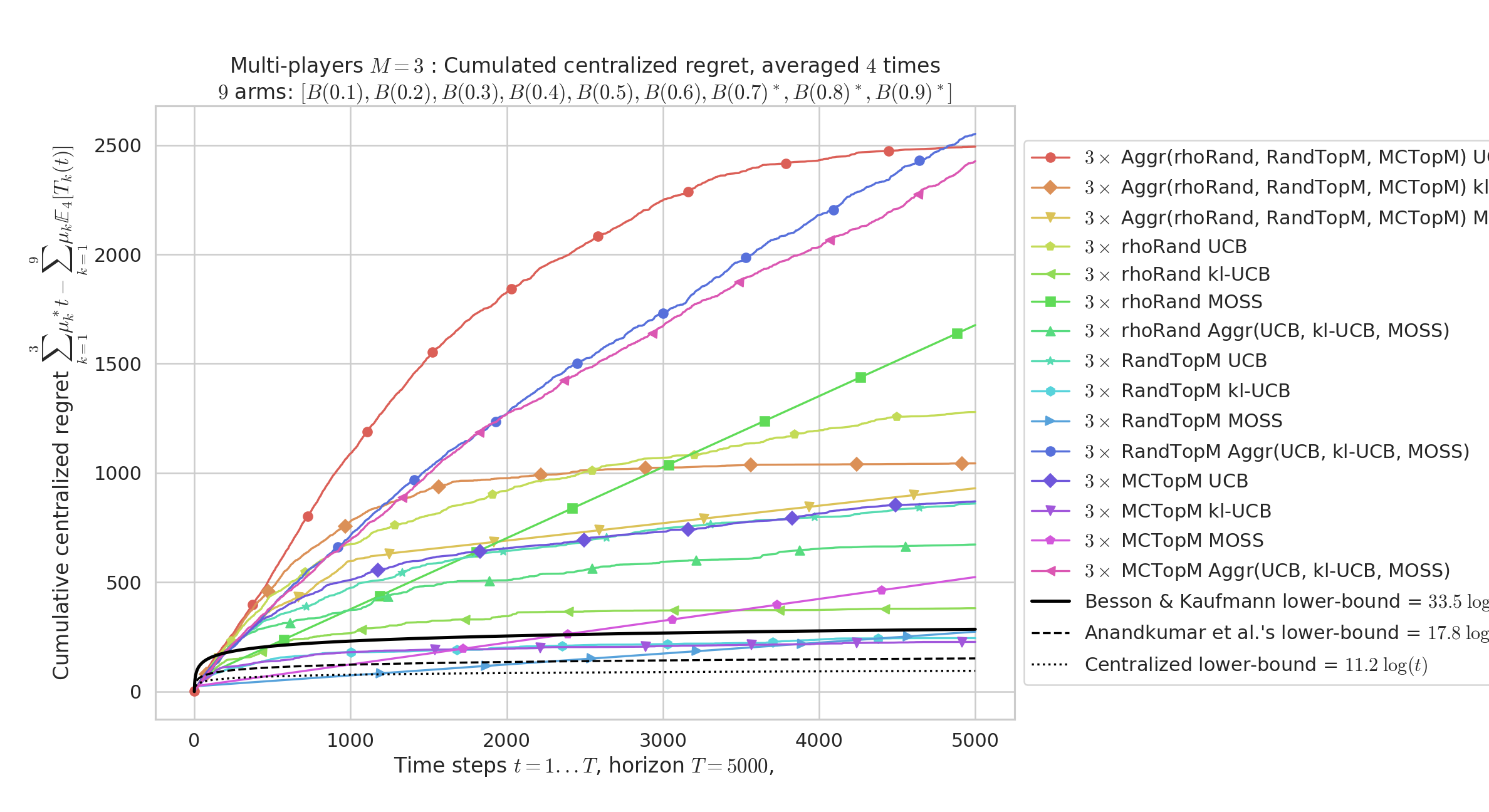
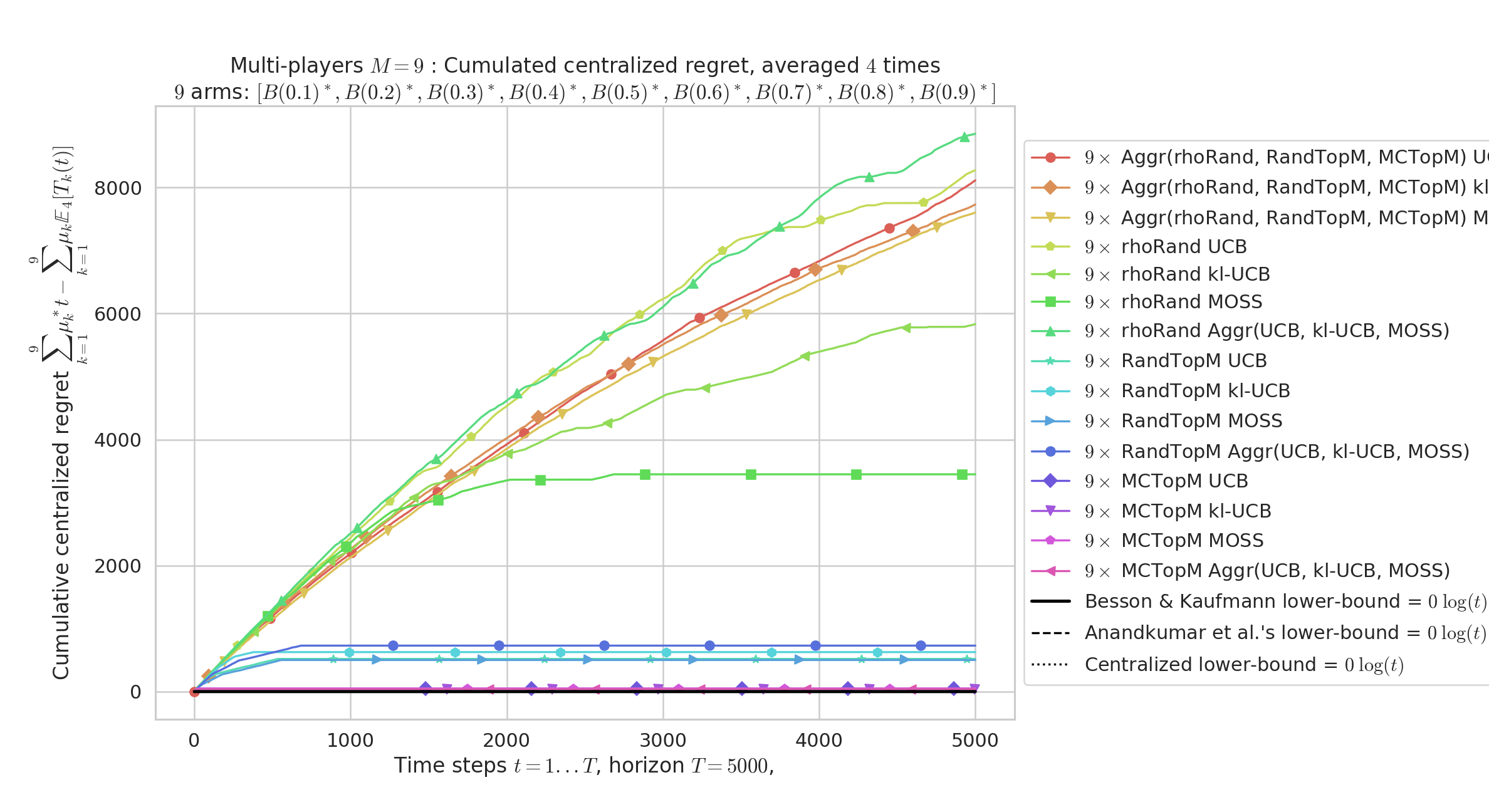
We focus on an example of a i.i.d. MAB problems, with channels divided in three groups: very bad arms (), average arms ( to ) and very good arms (). Horizon is (but it is unknown by the objects), and simulations are repeated times, to estimate the expected regret, is plotted below, as a function of . We compare the performance of and then objects (resp. in Figures 1 and 2), using one index policy along with one collision-avoidance protocol. We also simulate objects that use aggregation with Aggregator applied on one of the two levels. As expected, the objects using Aggregator perform worst than the best combination of algorithms, but better than some combination, in the two cases. Without knowing before-hand which combination is the best, the aggregation approach appears as a robust solution.
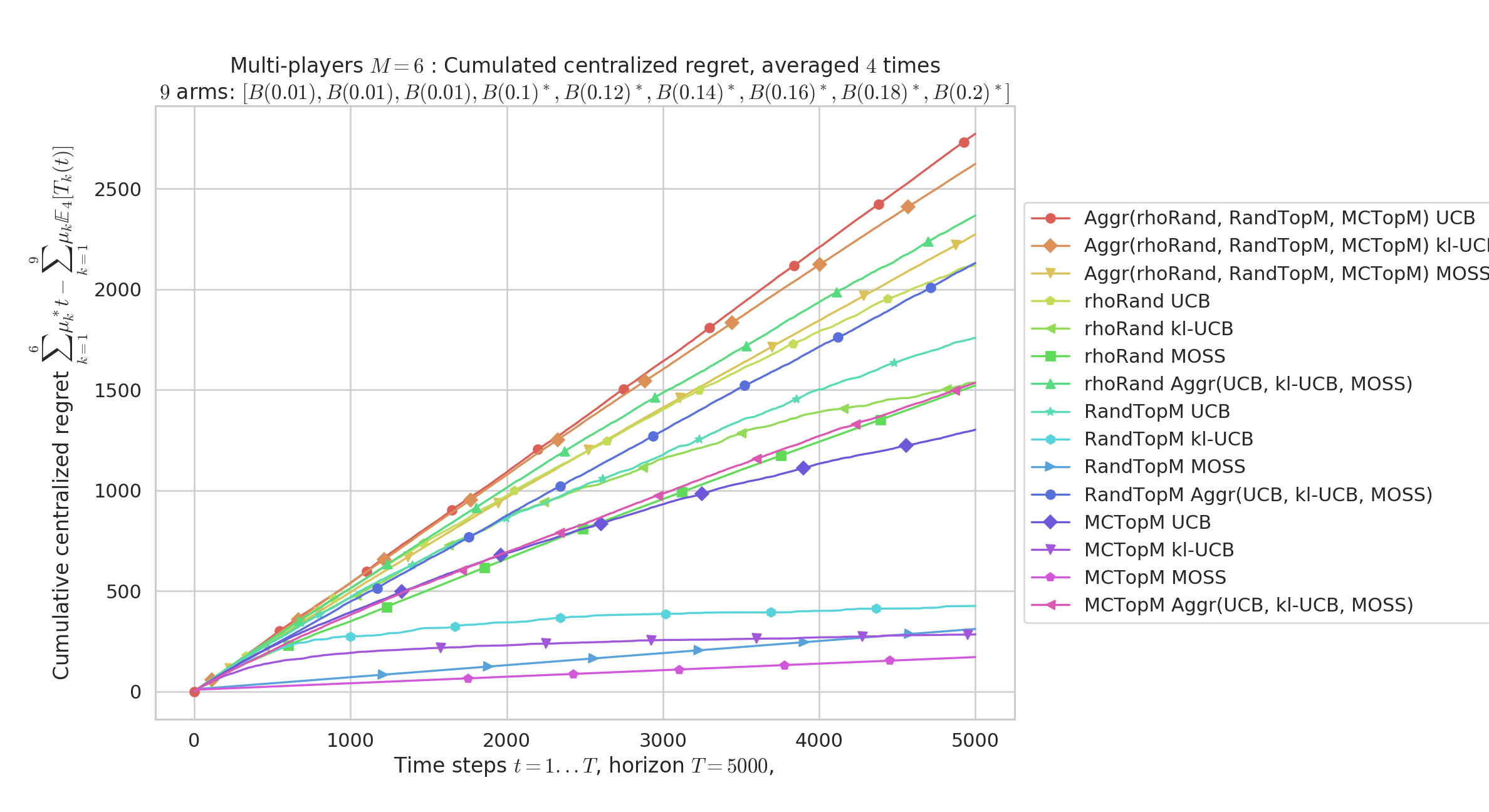
We present in Figure 3 a different problem with and devices. The conclusions are similar.
5 Conclusion
Aggregation algorithms can be useful in the framework of multi-player MAB applied for decentralized Cognitive Radio models. For the real-world application of our model, tuning parameters before-hand is no longer possible when facing unknown problem instances, and thus an adaptive algorithm is preferable. Our algorithm Aggregator was proved to be useful to let each object decide automatically its preferred strategy.
Future works Our combined approach does not have theoretical guarantees yet, exploring the theoretical developments is left as a future work. We will also work on a hardware implementation of our proposal.
Acknowledgements This work is supported by the French National Research Agency (ANR) with the project BADASS (N ANR-16-CE40-0002), the French Ministry of Research (MENESR) and École Normale Supérieure de Paris-Saclay.
Open Source
The code in Python used for the simulations and the figures [5],
is open-sourced at https://GitHub.com/SMPyBandits/SMPyBandits
and documented at https://SMPyBandits.GitHub.io.
References
- (2010) Opportunistic Spectrum Access with multiple users: Learning under competition. In IEEE INFOCOM, Cited by: §1, §1, §2, §3.2.
- (2002) Finite-time Analysis of the Multi-armed Bandit Problem. Machine Learning 47 (2), pp. 235–256. Cited by: §3.1.
- (2018) Aggregation of Multi-Armed Bandits Learning Algorithms for Opportunistic Spectrum Access. In IEEE Wireless Communications and Networking Conference, Barcelona, Spain. External Links: Link Cited by: §1, §3.1, §3.3.
- (2018) Multi-Player Bandits Revisited. In Algorithmic Learning Theory, Lanzarote, Spain. External Links: Link Cited by: §1, §2, §2, §3.1, §3.2.
- (2018) SMPyBandits: an Experimental Framework for Single and Multi-Players Multi-Arms Bandits Algorithms in Python. Note: Presentation paper, at hal.inria.fr/hal-01840022 External Links: Link Cited by: §5.
- (2012) Regret analysis of stochastic and nonstochastic multi-armed bandit problems. Foundations and Trends® in Machine Learning 5 (1), pp. 1–122. Cited by: §1, §1, §1, §3.1.
- (2011) The KL-UCB Algorithm for Bounded Stochastic Bandits and Beyond. In COLT, pp. 359–376. Cited by: §1, §3.1.
- (2010) Upper Confidence Bound based decision making strategies and Dynamic Spectrum Access. In IEEE International Conference on Communications (ICC), pp. 1–5. Cited by: §1.
- (1999) Cognitive Radio: making software radios more personal. IEEE Personal Communications 6 (4), pp. 13–18. Cited by: §1.
- (1933) On the Likelihood that One Unknown Probability Exceeds Another in View of the Evidence of Two Samples. Biometrika 25. Cited by: §3.1.
- (2007) A Survey of Dynamic Spectrum Access. IEEE Signal Processing magazine 24 (3), pp. 79–89. Cited by: §1, §1, §2.